
Top 20 Microservice interview questions for Advanced Spring Boot Developers in 2025
This blog covers the top 20 microservices interview questions, providing clear explanations and examples to help you prepare for your Spring Boot interviews. Topics range from the fundamentals of microservices architecture to advanced concepts like service discovery, API gateways, and distributed tracing.
Santosh Mane
January 31, 2025
15 min read
Introduction#
If you’re preparing for spring boot interviews, chances are you’ll come across some questions about microservices. They’re a big deal in tech right now, and I can tell you from experience, they’re definitely something you want to have a handle on. I’ve worked with Spring Boot enough to know how tricky these concepts can feel at first, so I decided to put together a list of the top 20 microservices interview questions I’ve seen asked. I’ll keep things simple, with clear examples to make sure you really get it. That way, you’ll be able to walk into your interview feeling ready and confident. Let’s get into it!
1. What is Microservices Architecture, and how is it different from Monolithic Architecture?#
Microservices Architecture is a way of building applications by breaking them down into small, independent services, each focused on a specific business function. These services are loosely coupled, meaning they can be developed, deployed, and scaled on their own without affecting the rest of the system.
On the other hand, Monolithic Architecture means everything is built into one big application. So, if one part of the system needs an update, you have to rebuild and redeploy the entire thing, which can slow things down.
Example:
- Monolithic: Think of a food delivery app where everything from managing customers to processing payments and tracking deliveries is packed into one massive codebase. If there’s an issue with the delivery part, the whole app could go down.
- Microservices: In this setup, you’d have separate services for "User Management," "Orders," "Payments," and "Delivery." So, if the "Delivery" service has a problem, the rest of the app keeps running smoothly.
2. What are the key benefits of using Microservices?#
The beauty of microservices is how they solve a lot of the pain points that come with monolithic systems. Here are some key benefits I’ve found:
- Scalability: Imagine you're running a big e-commerce site, and it’s sale season. You don’t need to scale the whole app—just the part that handles orders. Microservices let you scale services individually based on what needs more power. The "Orders" service can get a boost, while "User Management" can stay chill.
- Flexibility: One of the best things about microservices is that different teams can use different tech stacks. You could have one team working with Java, and another using Node.js. It all works together because each service is independent, and teams aren’t stuck using the same tech.
- Fault Isolation: If something breaks, you don’t have to worry about it taking the whole app down. For example, if the payment service goes down, your users can still browse and place orders. It's like having a safety net for your system.
- Faster Development: With microservices, teams can focus on their own services and work in parallel. Instead of waiting on each other, you can get things done faster. It’s like everyone working on different parts of the puzzle at the same time.
Example: Picture an e-commerce site during peak hours. The "Cart" service might need to scale up to handle the extra traffic, but other services—like "User Profiles" or "Shipping"—don’t need to change. The app keeps running smoothly while only the parts that need attention are scaled.
3. What is Service Discovery, and why is it important in Microservices?#
Service Discovery enables Microservices to dynamically find and communicate with each other. This is critical in distributed systems where services can scale up or down, and their network locations might change.
Example:
- Without Service Discovery: Each service’s address must be hardcoded, making it brittle and hard to maintain.
- With Service Discovery: Tools like Netflix Eureka or Consul allow services to register themselves and look up other services using a central registry. For example, the "Orders" service can find the "Payments" service without needing to know its exact location.
4. What is an API Gateway, and how does it work in Microservices?#
An API Gateway acts as the single entry point for all client requests, routing them to the appropriate Microservices. It also provides additional functionalities like authentication, rate limiting, and caching.
Example: Imagine a food delivery app. Instead of clients calling the "User," "Orders," and "Payments" services separately, they call the API Gateway. The Gateway handles the routing and returns aggregated responses, simplifying client-side logic.
Tool: Spring Cloud Gateway or Zuul can be used to implement API Gateways.
5. How do Microservices communicate with each other?#
Microservices communicate primarily using:
- Synchronous communication: REST APIs or gRPC. For instance, the "Orders" service may call the "Payments" service via an HTTP request to process a transaction.
- Asynchronous communication: Message brokers like RabbitMQ, Kafka, or ActiveMQ. For example, an "Order Created" event might trigger a "Notification" service to send an email.
Example:
- The "User Management" service sends a message to Kafka when a new user registers and the "Email" service listens to this event to send a welcome email.
6. What is a Circuit Breaker, and why is it important?#
A Circuit Breaker prevents cascading failures in Microservices by temporarily stopping calls to a failing service. If failures exceed a threshold, it "opens," blocking requests. After a cooldown, it moves to a half-open state to test if recovery is possible. If successful, it closes and resumes normal operation.
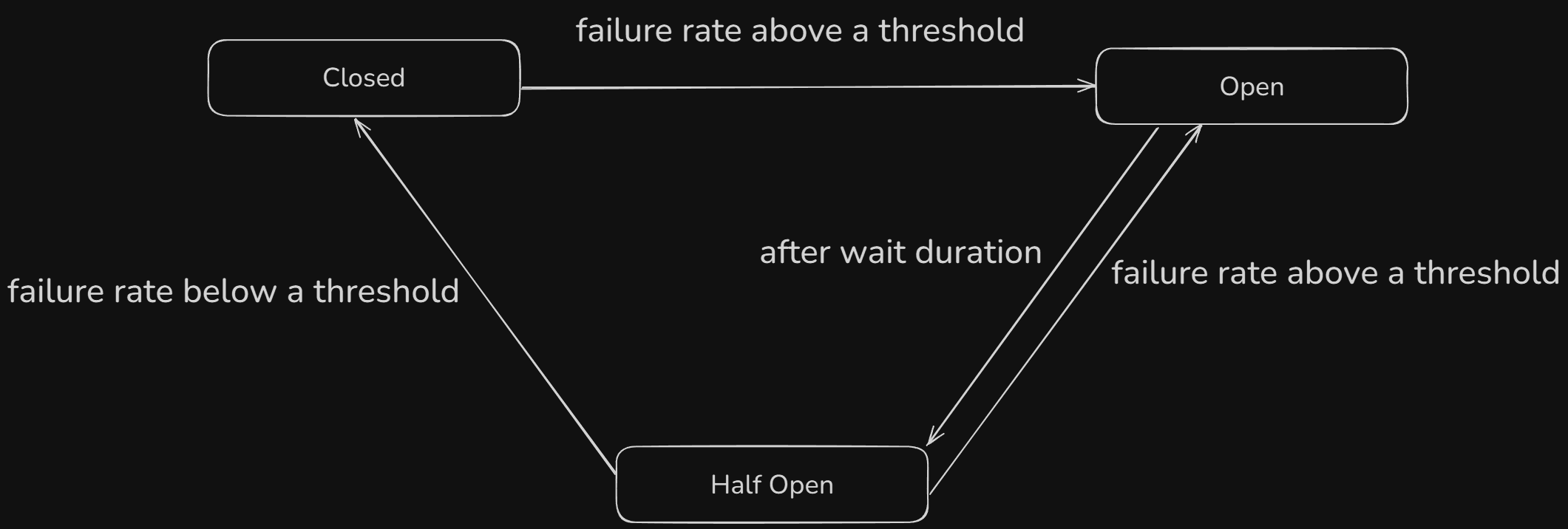
Example:
If the "Payments" service is down, the "Orders" service can skip payment processing and notify the user instead of waiting indefinitely.
Implementation: Can be implemented using Resilience4j with Spring Boot to configure failure thresholds and recovery log
7. What is Retry Mechanism, and how does it work?#
A Retry Mechanism automatically retries failed requests after a specified interval, often with an exponential backoff strategy.
Example: If the "Inventory" service fails due to a temporary network glitch, the "Orders" service retries the request after 1 second, then 2 seconds, and so on until a maximum number of attempts.
Tool: Resilience4j Retry module can handle this.
8. What is Rate Limiting, and how do you implement it?#
Rate Limiting restricts the number of requests a client can make to protect services from being overwhelmed.
Example: A public API might allow only 100 requests per minute per user. If a user exceeds this limit, further requests are denied until the time resets.
Implementation: It can be implemented using Resilience4j
9. What are Gateway Filters, and how do you use them?#
Gateway Filters modify incoming requests or outgoing responses in an API Gateway. You can use them for tasks like logging, authentication, or adding custom headers.
Example: A filter can check if a request has a valid authentication token before forwarding it to the "Orders" service.
10. How do you implement Authentication in Gateway Filters?#
In Spring Cloud Gateway, authentication can be implemented using a custom gateway filter to intercept and validate requests before they reach backend services.
- Create a Custom Filter: Implement a filter that checks for an
Authorizationheader in the request (usually with a JWT token). - Validate the Token: Use a service (e.g.,
JwtService) to parse and validate the JWT token, ensuring it’s valid and not expired. - Add User Info: After validating, extract user details (like user ID) from the token and add them to the request headers, so downstream services can access them.
- Return Unauthorized for Invalid Tokens: If the token is missing or invalid, return a
401 Unauthorizedresponse
Example:
11. What is a Centralized Configuration Server?#
A Centralized Configuration Server stores and manages configuration files for all services in one place. It ensures consistency and allows dynamic updates without redeploying services.
Example: Spring Cloud Config Server reads configurations from a Git repository and serves them to Microservices.
12. What is Distributed Tracing, and how do you implement it?#
Distributed tracing allows you to monitor and troubleshoot microservices by tracking requests as they travel through various services in a distributed system. By providing a clear view of a request's lifecycle, it helps identify performance bottlenecks, latency, and failures across services.
How to Implement Distributed Tracing:
- Choose a Tracing Solution: You can use tracing libraries like Micrometer and Zipkin for distributed tracing in Spring Boot applications.
- Add Dependencies:
micrometer-observation: Collects and exports tracing and metric data.micrometer-tracing-bridge-brave: Bridges Brave (used by Zipkin) with Micrometer for tracing.zipkin-reporter-brave: Sends trace data to Zipkin for visualization.feign-micrometer: Integrates Feign client with Micrometer for tracing outbound requests.
- Configure Application:
- Expose management endpoints to view trace data (
management.endpoints.web.exposure.include). - Set the sampling probability for traces (
management.tracing.sampling.probability). - Set the Zipkin URL to send trace data (
spring.zipkin.baseUrl).
- Expose management endpoints to view trace data (
- View Traces: Use Zipkin's UI to view the traces and analyze how requests flow through your services, helping you pinpoint latency or errors.
Example Configuration:
13. What is Micrometer, and how does it help in Monitoring?#
Micrometer is a metrics collection and monitoring library designed for Java applications. It provides a simple and consistent way to collect application metrics and expose them to monitoring systems, such as Prometheus, Grafana, Datadog, and others. Micrometer integrates seamlessly with Spring Boot and other Java frameworks to provide out-of-the-box support for various monitoring solutions.
How Micrometer Helps in Monitoring:
- Collect Metrics: Micrometer allows you to collect various types of metrics, such as:
- Counters: Count events like requests, errors, or transactions.
- Gauges: Measure values like memory usage or thread counts.
- Timers: Measure the time taken for operations, such as request processing times.
- Distribution Summary: Track statistical data like request sizes or durations.
- Expose Metrics to Monitoring Systems: Micrometer exposes these metrics via HTTP endpoints or directly to monitoring systems, such as Prometheus, which can then visualize the metrics in dashboards (e.g., Grafana).
- Integrate with Spring Boot: Spring Boot integrates Micrometer out-of-the-box, enabling easy exposure of metrics without much configuration. It also automatically collects common metrics like HTTP request durations, database query times, and more.
- Real-Time Monitoring: With Micrometer, you can monitor the health, performance, and usage of your application in real time, helping you identify issues, track SLA compliance, and improve overall performance.
Example Configuration:
If you're using Prometheus for monitoring:
14. What is ELK Stack?#
In a microservices architecture, multiple services generate logs, and managing these logs can be complex. The ELK Stack helps to aggregate, store, and visualize logs from all services, making it easier to monitor, debug, and analyze microservices.
ELK Stack is a set of open-source tools used for searching, analyzing, and visualizing log data in real-time. It consists of three main components:
- Elasticsearch: A distributed search and analytics engine that stores and indexes log data.
- Logstash: A data processing pipeline that collects, parses, and forwards log data to Elasticsearch.
- Kibana: A data visualization tool that provides a web interface to interact with and analyze the data stored in Elasticsearch.
15. What is Docker, and how does it help in Microservices?#
Docker is a platform that packages applications and their dependencies into containers, ensuring consistency across different environments. Containers are lightweight, portable, and isolated, making them ideal for deploying and running microservices.
How Docker Helps in Microservices:
- Isolation: Each microservice runs in its own container, preventing conflicts and ensuring independence.
- Portability: Containers ensure that microservices run consistently across all environments (dev, staging, production).
- Scalability: Easily scale microservices by running multiple container instances.
- Efficiency: Containers share the host OS kernel, making them more resource-efficient than VMs.
Example:
In a microservices setup:
- Service A (User service) is packaged in Docker as
user-service-container. - Service B (Order service) is packaged in Docker as
order-service-container. - Both containers communicate via Docker's internal network, and can be scaled independently.
Using Docker Compose or Kubernetes, these containers can be deployed, scaled, and managed effectively, ensuring that each microservice runs in its isolated, consistent environment.
16. What is Kubernetes, and how does it manage Microservices?#
Kubernetes orchestrates containerized applications. It manages deployment, scaling, and load balancing for Microservices.
Example: Deploying the "Orders" service on Kubernetes:
17. What are the challenges of Microservices Architecture?#
- Complexity:
- Example: In an e-commerce platform with multiple microservices (User Service, Order Service, Payment Service), managing, deploying, and monitoring all services becomes complex. Ensuring they work together smoothly requires careful orchestration.
- Distributed System Issues:
- Example: If the Order Service and Payment Service are on different servers, network latency or failure between them could lead to delays in processing, resulting in inconsistent user experience or failure to complete an order.
- Data Management:
- Example: If the Inventory Service and Order Service have separate databases, ensuring that inventory levels are updated correctly when an order is placed requires complex synchronization, and managing eventual consistency might introduce data inconsistencies.
- Service Communication:
- Example: The User Service may need to call the Order Service to get the order history. Deciding between synchronous (REST) or asynchronous (message queues) communication and managing retries, timeouts, and failures can become tricky.
- Deployment and Monitoring:
- Example: In a microservices-based ride-hailing app, deploying multiple services like Driver Service, Passenger Service, and Payment Service independently while ensuring each service is up-to-date, and monitoring their performance across the distributed system, is a major challenge without automation tools like Kubernetes.
- Security:
- Example: In a banking application, different services like Account Service, Transaction Service, and Fraud Detection Service may need to communicate over insecure networks. Managing secure communication, ensuring proper authorization between them, and protecting user data becomes more complex with each service.
- Testing:
- Example: Testing a flow where User Service creates a user and Order Service processes the order involves testing both individual services and their interactions. This requires complex integration tests and mock data for services that are not available locally.
- Versioning and Compatibility:
- Example: If the Payment Service updates its API to include a new feature, older versions of the Order Service might not be compatible with the new version. Ensuring backward compatibility while rolling out new versions can be complex, especially if services evolve independently.
18. How do you handle Data Consistency in Microservices?#
To handle Data Consistency in Microservices, two main approaches are commonly used:
- Eventual Consistency:
- Data across services may not be immediately consistent but will eventually become consistent over time.
- Services communicate through events (e.g., via a message broker like Kafka) to propagate updates asynchronously.
Example: After a payment is processed in the Payment Service, it emits a "Payment Successful" event. Other services, like the Order Service, subscribe to this event and update the order status accordingly.
- Saga Pattern:
- The Saga Pattern manages distributed transactions by breaking them down into a series of local transactions across multiple services.
- If any transaction fails, compensating actions are triggered to revert changes made by previous steps.
Example:
- Order Service creates an order.
- Payment Service processes the payment.
- Inventory Service deducts stock.
- If payment fails, the saga triggers compensating actions, such as canceling the order and restoring stock.
Both approaches ensure loose coupling between services and maintain consistency across distributed systems without requiring a single, centralized database.
19. What is the Saga Pattern, and how does it work?#
The Saga Pattern ensures data consistency in distributed systems by breaking a transaction into smaller, independent local transactions that are coordinated across multiple services. If a step fails, compensating transactions are executed to maintain consistency.
There are two main approaches to implementing the Saga Pattern:
1. Choreography-Based Saga
In this approach, each service reacts to events published by other services without a central coordinator.
Example: E-commerce Order Processing (Choreography)
- The Orders Service creates an order and publishes an
OrderCreatedevent. - The Inventory Service listens to this event, reserves stock, and publishes an
InventoryReservedevent. - The Payments Service listens for
InventoryReserved, processes the payment, and publishes aPaymentProcessedevent.
Failure Handling:
- If payment fails, the Payments Service publishes a
PaymentFailedevent. - The Inventory Service listens for
PaymentFailedand restocks the item. - The Orders Service listens for
PaymentFailedand cancels the order.
Pros: Decentralized and loosely coupled.
Cons: Becomes complex with too many services and event dependencies.
2. Orchestration-Based Saga
In this approach, a central Saga Orchestrator manages the entire process by calling services in a predefined order.
Example: E-commerce Order Processing (Orchestration)
- The Saga Orchestrator starts the process and asks the Orders Service to create an order.
- Once the order is created, the Orchestrator calls the Inventory Service to reserve stock.
- If successful, it then calls the Payments Service to process payment.
Failure Handling:
- If payment fails, the Orchestrator triggers compensating transactions:
- Calls the Inventory Service to release stock.
- Calls the Orders Service to cancel the order.
Pros: Centralized control and clear transaction flow.
Cons: Single point of failure (orchestrator) and tight coupling.
Choosing Between Choreography and Orchestration
- Use Choreography if you have a simple workflow with a few services.
- Use Orchestration for complex workflows that require better control and error handling.
Both approaches ensure distributed transaction consistency while balancing scalability and maintainability.
20. What is Canary Deployment, and how is it useful?#
Canary Deployment is a progressive release strategy where a new version of an application is deployed to a small subset of users before a full rollout. This minimizes risk by enabling real-world testing while keeping the majority of users on the stable version.
How It Works:
- A small percentage (e.g., 5%) of traffic is directed to the new version.
- Performance, stability, and error metrics are monitored.
- If no issues arise, traffic gradually increases (e.g., 25%, 50%, then 100%).
- If problems occur, traffic is redirected to the stable version, preventing widespread issues.
Example: Canary Deployment for an E-commerce Orders Service
A company releases a new version of its Orders Service:
- Initially, 5% of users are directed to the new version (
v2). - The system monitors error rates, latency, and user feedback.
- If stable, traffic increases incrementally to 25%, 50%, and 100%.
- If issues occur, traffic rolls back to the previous version (
v1).
Conclusion#
I hope this list of top 20 microservices interview questions helps you feel more prepared and confident for your upcoming interview. Microservices can seem overwhelming at first, but with a solid understanding of their core concepts, you'll be ready to tackle any question that comes your way. Keep practicing, and you'll surely impress your interviewers with your knowledge and insights into microservices architecture.


