Kafka In Spring Boot — Effortless Messaging Made Easy
This article explores Apache Kafka, highlighting its high-throughput, low-latency real-time data processing capabilities and integration with Spring Boot. It covers Kafka's architecture, fault tolerance, and the transition to KRaft mode for improved scalability in modern distributed systems.
Shreya Adak
December 17, 2024
10 min read
Introduction#
Apache Kafka is an open-source distributed event streaming platform designed for high-throughput, low-latency real-time data processing. Initially developed by LinkedIn and later donated to the Apache Software Foundation, it is widely used for real-time pipelines and streaming applications.
Why Kafka is Essential in Distributed Systems#
As distributed systems grow, traditional request-response communication struggles with challenges like:
- Handling Large Data Streams: Managing high-velocity data efficiently.
- Decoupling Services: Allowing independent evolution of services without tight dependencies.
- Ensuring Fault Tolerance: Avoiding data loss and maintaining reliability during failures.
Kafka addresses these problems by being horizontally scalable, fault-tolerant, and fast. It follows a publish-subscribe (pub-sub) model, enabling producers to write and consumers to read messages independently. This decoupling ensures seamless communication between systems.
Key Concepts of Apache Kafka#
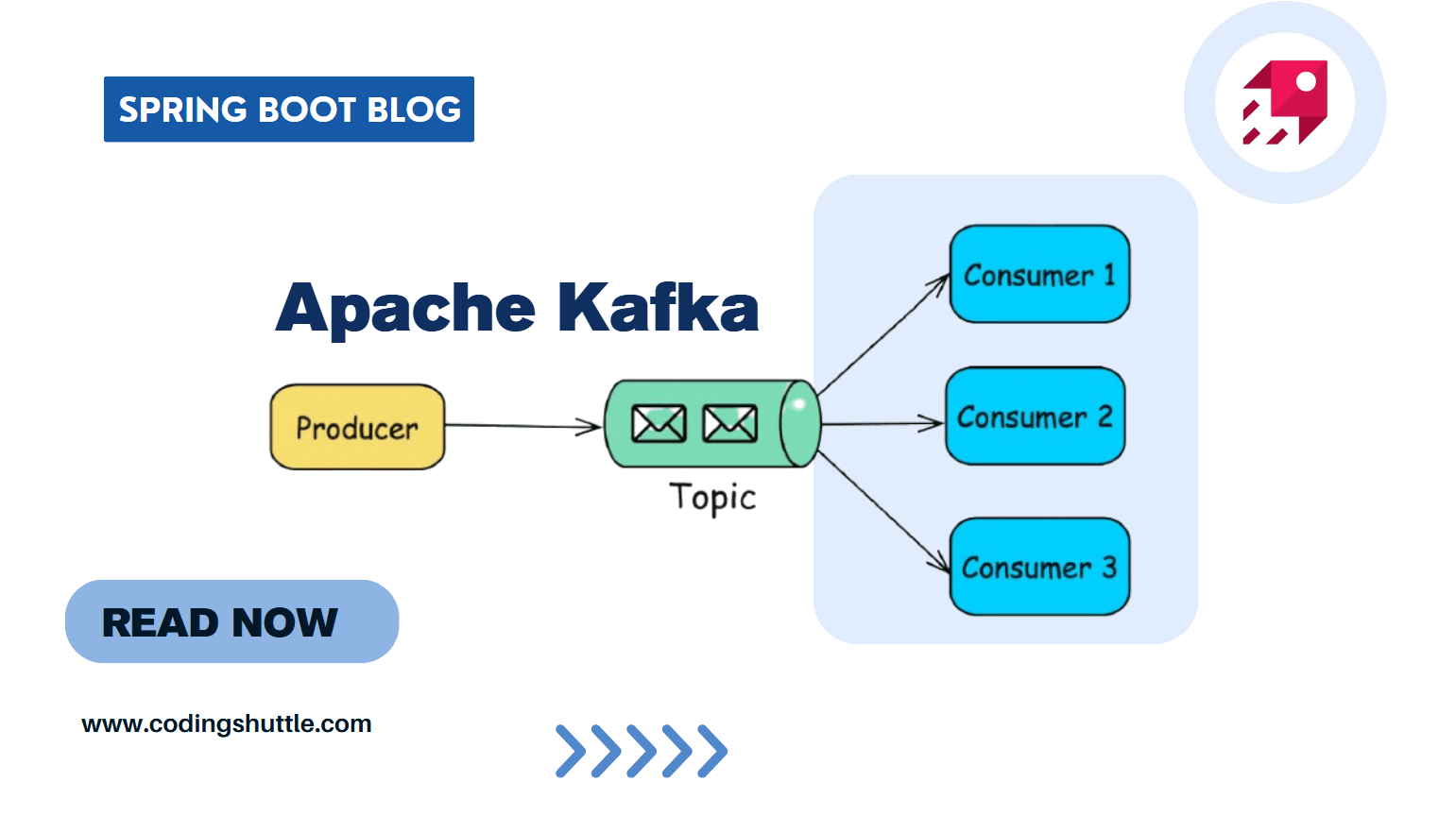
Topics:
Data in Kafka is organized into topics. A topic is a logical channel where messages are written (produced) by producers and read (consumed) by consumers.
Producers:
Producers are the entities that publish (write) messages to Kafka topics.
Consumers:
Consumers are the entities that subscribe to Kafka topics to read (consume) messages.
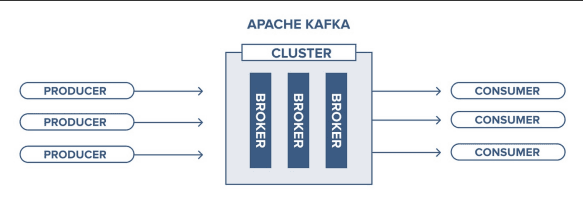
Brokers:
Kafka runs as a cluster of one or more servers called brokers, which store and manage the data. Each broker is responsible for maintaining a portion of the data.
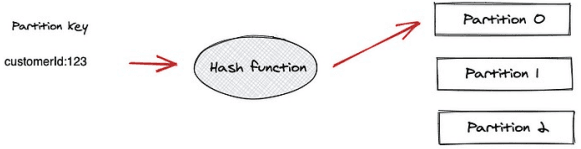
Partitions:
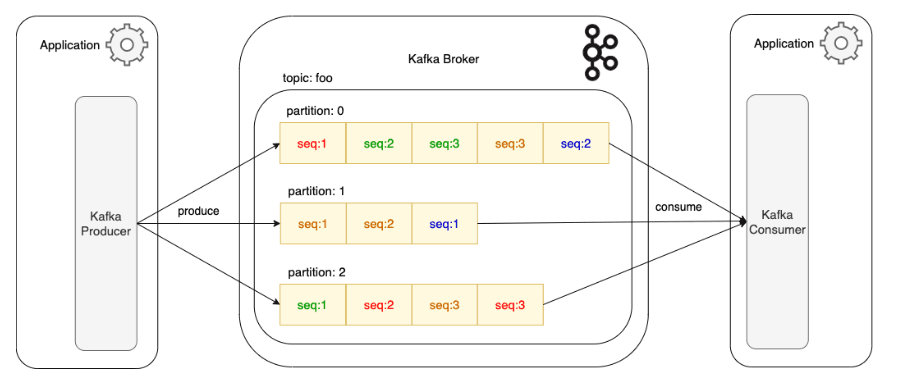
Topics are split into partitions to enable parallel processing and scalability. Each partition is an ordered log of messages.
Offset:
Each message in a partition has a unique offset that serves as its identifier, ensuring that the messages are processed in order.
Replication:
Kafka replicates data across brokers for fault tolerance. This ensures that data is available even if a broker fails.
Use Cases of Apache Kafka#
Real-Time Data Processing:
Process streams of data in real-time, such as website activity tracking.
Log Aggregation:
Collect and aggregate logs from multiple systems into a single source.
Event Sourcing:
Store events as a log for systems where state changes need to be captured reliably.
Data Integration:
Stream data between various systems and databases, making it an excellent tool for creating data pipelines.
Analytics:
Process and analyze data streams to derive insights, such as monitoring user behavior or fraud detection.
Why Use Kafka?#
- High Performance: Kafka is designed to handle large volumes of data with low latency.
- Scalability: It can scale horizontally by adding more brokers and partitions.
- Durability: Kafka persists data to disk and replicates it across brokers for fault tolerance.
- Flexibility: It supports both real-time and batch processing.
- Decoupling Systems: Kafka acts as an intermediary, reducing the dependency between producers and consumers.
When NOT to Use Kafka#
- Simple Request-Response: Use REST APIs or gRPC for synchronous communication.
- Small Projects: Kafka is overkill; consider RabbitMQ or ActiveMQ.
- High Latency Tolerance: Use database polling or batch jobs instead.
- Monolithic Apps: Kafka adds unnecessary complexity; better for microservices.
Key Features of Kafka#
Massive Scalability:
Kafka can scale across 100s of nodes, making it suitable for large distributed systems.
High Throughput:
It can process hundreds of MB/s and millions of messages per second.
Low Latency:
Kafka delivers messages with latencies as low as 2ms, ensuring real-time responsiveness.
Fault Tolerance:
With data replication, Kafka ensures reliability and prevents data loss in case of failures.
Example#
Imagine an e-commerce platform:
- Order System (Producer): Sends order events (e.g., "Order Placed").
- Kafka: Receives and stores these events in a topic called "orders."
- Warehouse System (Consumer): Subscribes to the "orders" topic to process fulfillment.
NOTE: LinkedIn uses Kafka to process 1 Billion messages per day
The Kafka Architecture#
1. Partitioning of Topics: Kafka splits topics into partitions, enabling parallel processing. Each message is assigned to a partition based on a key or round-robin.
Imagine a library (Kafka topic) that stores books (messages). The library has several shelves (partitions), and each book needs to be placed on a shelf.
2. Message Ordering: Kafka guarantees ordering within a partition, but not across partitions. Imagine the post office is responsible for delivering letters (messages) to different addresses (consumers). However, there are multiple postal workers (partitions) in the post office, each handling a different type of letter. The post office ensures that the letters are delivered in the exact order they are received, but this guarantee is only for letters handled by the same postal worker (partition). If the letters are handled by different postal workers, their order might not be the same.
3. Message Re-reading by Consumers: Yes, consumers can read the same message multiple times within the retention period (default 7 days), as Kafka stores messages and tracks consumer offsets.
Just like a librarian can re-check books (messages) multiple times during their availability in the library (within the retention period), Kafka consumers can re-read the same message as long as it is within the configured retention period. Kafka keeps track of consumer offsets, allowing them to go back and read older messages, ensuring flexibility and reprocessing capabilities for the consumers.
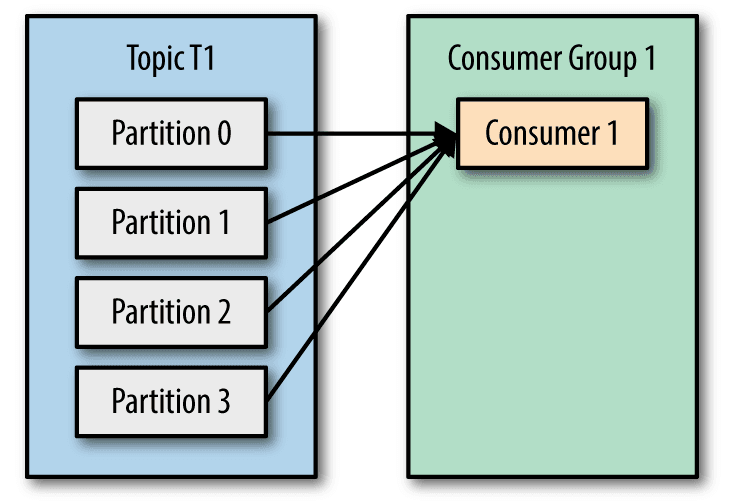
4. Adding New Consumers: When a new consumer joins a group, Kafka rebalances partition assignments. Consumers may start reading from new or multiple partitions.
Just like a library efficiently assigns books (partitions) to librarians (consumers) to manage the workload, Kafka ensures that when a new consumer joins, it rebalances the partitions. This allows the system to handle more traffic (messages) efficiently by distributing the load across more consumers, ensuring high availability and parallel processing.
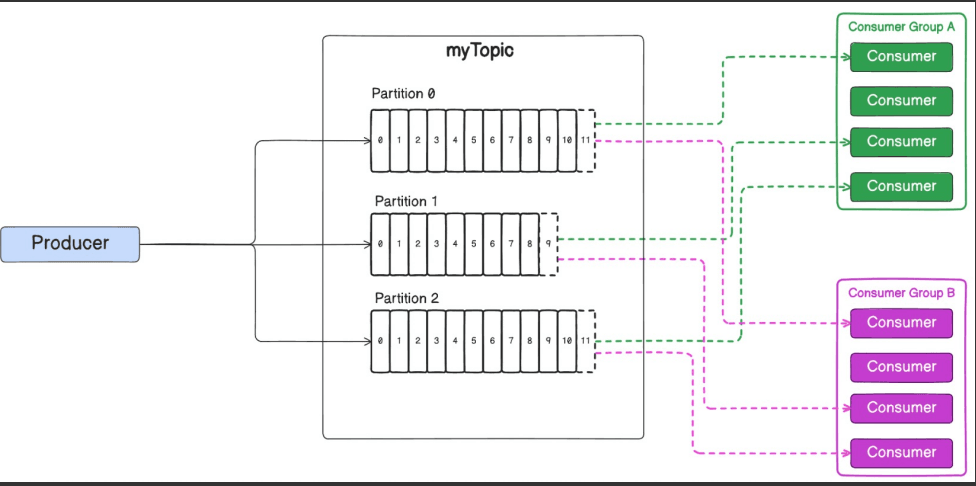
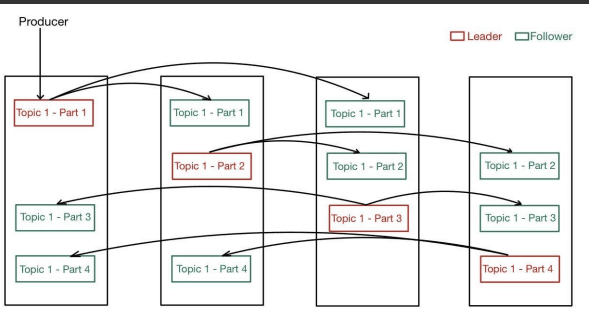
5. Broker Failures: Kafka ensures fault tolerance via replication. If a broker goes down, a replica takes over as the leader, and consumers continue reading from available brokers.
In the real world, the team of chefs ensures that the kitchen keeps working even if one chef (broker) becomes unavailable by relying on backup chefs (replicas). Kafka’s replication mechanism ensures that even if a broker fails, the system remains fault-tolerant, and consumers can continue to process messages without disruption.
6. Message Availability After Days: Consumers can read messages that are within the configured retention period, even if produced days ago. In the real world, the library system ensures that books (messages) are available for borrowing (consumption) within a certain timeframe, after which they are removed. Similarly, in Kafka, consumers can read messages that are still within the configured retention period, even if the messages were produced days ago.
This design allows Kafka to offer scalability, reliability, and fault tolerance in distributed systems.
- Traditional Architecture (ZooKeeper-based): Kafka used ZooKeeper for cluster management, metadata, and leader election.
- Kafka Raft (KRaft) Mode: Replaces ZooKeeper with the Raft consensus protocol, simplifying metadata management, leader election, and scalability.
- Benefits of KRaft:
- Simplified architecture with no ZooKeeper dependency.
- Improved scalability and fault tolerance.
- Easier management and better performance.
Kafka is transitioning to KRaft mode for a more streamlined, efficient distributed system.
How to work with Apache Kafka in Spring Boot#
Working with Apache Kafka in Spring Boot involves setting up Kafka producers and consumers to handle messages. Here’s a step-by-step guide:
Build two projects one acts as producer another act as consumer with kafka dependency
- Project 1 acts as a Kafka Producer
- Project 2 acts as a Kafka Consumer
Step: 1. Add Dependencies#
Both projects need the Spring Kafka dependency.
Maven Dependency:#
Add this to pom.xml for both projects:
Or when you build your project using https://start.spring.io/ you add these dependencies.
Next configured the kafka (inside yaml or properties)
Step:2. Producer Configuration (Project 1)#
application.yml (Producer):#
You can also configure your database and port according to what you want inside the properties or YAML file.
Create Kafka Topic Configuration:#
Kafka will auto-create a topic if it does not exist. However, it's a good practice to explicitly configure it:
return new NewTopic(KAFKA_TOPIC, 3, (short) 1);:
- This creates a Kafka topic with the following parameters:The
NewTopicclass is used to create and configure topics in Kafka.KAFKA_TOPIC: This is the name of the Kafka topic, which is injected from the properties file (e.g.,"message-topic").3: This is the number of partitions for the topic. It indicates how many partitions the topic will have. More partitions mean more parallelism and scalability.(short) 1: This is the number of replicas for the topic. In this case, there will be one replica for the topic, which provides redundancy and fault tolerance.
- When we run and hit the endpoint
- The consumer subscribes to
massage-topic(created with 3 partitions). - Kafka assigns 3 partitions to the consumer (
massage-topic-0,massage-topic-1, andmassage-topic-2). - The consumer starts receiving messages and processes them (e.g., the message
"hiii").
- The consumer subscribes to
Producer Controller:#
Create a REST endpoint to trigger sending messages.
Step:3. Consumer Configuration (Project 2)#
application.yml (Consumer):#
Consumer Service:#
This class listens to messages from the Kafka topic.
Note: By default, auto.create.topics.enable is true, allowing Kafka to automatically create topics with default settings when producers or consumers interact with non-existent topics.
Step:4. Start Kafka Server#
1. Download Kafka:
Visit Kafka's Quickstart Page:
Go to the official Kafka Quickstart page to get the latest version.
Download the Latest Version: You can either download the Kafka release directly from the official site or use the following link to fetch the version 3.9.0:
Download from official mirror: Download Kafka 3.9.0
2. Extract Kafka
- After downloading the
.tgzfile, use the following command to extract it:
$ tar -xzf kafka_2.13-3.9.0.tgz
$ cd kafka_2.13-3.9.0
This will extract the contents of Kafka into a folder named kafka_2.13-3.9.0.
3. Start the Kafka environment
NOTE: Your local environment must have Java 8+ installed.
Kafka Modes: KRaft or ZooKeeper
Kafka can run in two configurations: KRaft mode or ZooKeeper mode. Follow the steps below for KRaft mode.
Kafka with KRaft (Without ZooKeeper):
- For Mac:
- Generate a Cluster UUID:
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
- Format Log Directories:
$ bin/kafka-storage.sh format --standalone -t $KAFKA_CLUSTER_ID -c config/kraft/reconfig-server.properties
- Start the Kafka Server:
$ bin/kafka-server-start.sh config/kraft/reconfig-server.properties
- Generate a Cluster UUID:
- For Windows:
- Generate a Cluster UUID:
- Using PowerShell
KAFKA_CLUSTER_ID="$(bin/windows/kafka-storage.bat random-uuid)"- Windows Command Prompt
i. Generate
bin\windows\kafka-storage.bat random-uuid
ii. Set KAFKA_CLUSTER_ID
set KAFKA_CLUSTER_ID=<Created ID>
- Windows Command Prompt
- Using PowerShell
- Format Log Directories:
- Using PowerShell
bin/windows/kafka-storage.bat format -t $KAFKA_CLUSTER_ID -c config/kraft/reconfig-server.properties
- Windows Command Prompt
bin\windows\kafka-storage.bat format -t %KAFKA_CLUSTER_ID% -c config\kraft\reconfig-server .properties --standalone
- Using PowerShell
- Start the Kafka Server:
- Using PowerShell
bin/windows/kafka-server-start.bat config/kraft/reconfig-server.properties
- Windows Command Prompt
bin\windows\kafka-server-start.bat config\kraft\reconfig-server.properties
- Using PowerShell
- Generate a Cluster UUID:
Step:5. Run Producer and Consumer#
- Run Project 1 (Producer Application).
- Run Project 2 (Consumer Application).
- Send a message using the Producer's endpoint:
http://localhost:8010/hiii
- The Consumer will log the received message:

Conclusion#
This article provides an overview of Apache Kafka, emphasizing its role in distributed systems by ensuring scalability, fault tolerance, and high performance. It covers Kafka's architecture, real-time use cases, and practical integration with Spring Boot for efficient data processing and service decoupling. Kafka is a powerful event streaming platform for handling real-time data at scale, suitable for diverse applications but should be chosen based on project needs and complexity.
Want to Master Spring Boot and Land Your Dream Job?
Struggling with coding interviews? Learn Data Structures & Algorithms (DSA) with our expert-led course. Build strong problem-solving skills, write optimized code, and crack top tech interviews with ease
Learn more
